Jump Consistent Hash
오늘 소개할 내용은 단 코드 10줄에 불과하다!
// Hash consistently chooses a hash bucket number
// in the range [0, numBuckets) for the given key.
// numBuckets must be >= 1.
func Hash(key uint64, numBuckets int) int32 {
var b int64 = -1
var j int64
for j < int64(numBuckets) {
b = j
key = key*2862933555777941757 + 1
j = int64(float64(b+1) * (float64(int64(1)<<31) / float64((key>>33)+1)))
}
return int32(b)
}
Consistent Hash
Consistent hash에 대해 들어본 적이 있는가? Consistent hash는 1997년 David Karger 등에 의해 처음 소개된 개념이다. 당시에는 분산 네트워크 환경에서 캐시들을 어떻게 잘 나눠 저장할지에 대해 고민을 하고 있었다고 한다. 처음 생각한 가장 단순한 방법은 캐시할 대상을 해시한 값을 통해 골고루 분산시키는 것이었다. 즉 캐시 서버가 N개가 있을 경우 obj라는 객체를 hash(obj) % N번째 캐시 서버에 저장하는 것이다. 하지만 새로운 캐시 서버가 추가 또는 제거되는 경우 각 객체에 대응되는 캐시 서버는 거의 모두 바뀐다. 실로 재앙이 아닐 수 없다.
당시에 고안된 해법이 바로 consistent hash 함수이다. 논문에선 consistent hash를 balance, monotonicity, spread, load 네 가지 속성을 만족시키는 해시 함수로 정의한다. 다만 당시에 정의된 해시 함수는 클라이언트가 알고 있는 캐시 서버의 종류가 다를 수 있는 경우를 대상으로 했기 때문에 Jump Consistent Hash 등의 다른 consistent hash 알고리즘까지 포함하기 위해서는 조금 정의가 수정될 필요가 있다. Jump Consistent Hash는 네 가지 속성 중 balance와 monotonicity 속성을 만족하는 해시 함수이다. 각 속성의 의미하는 바는 다음과 같다.
- balance: 저장할 객체들은 각각의 버킷들에 고르게 분포되어야 한다. (objects are evenly distributed among buckets)
- monotonicity: 버킷의 개수가 증가할 때 객체들은 새로 추가된 버킷으로만 이동한다. 즉 기존 버킷간의 불필요한 이동은 전무하다. (when the number of buckets is increased, objects move only from old buckets to new buckets)
위 내용을 기호를 사용해서 좀더 엄밀히 정의해보자. 총 버킷의 갯수를 $N$, 모든 객체의 집합을 $\mathbb{X}$, consistent hash 함수를 $h$라고 하면 다음과 같이 표현할 수 있다.
balance 속성은 다음과 같이 표현된다
monotonicity 속성은 다음과 같이 쓸 수 있다.
Jump Consistent Hash는 단순히 위의 수학적 정의를 구현한 함수에 불과하다!
Jump Consistent Hash 구현하기
그래서 우리가 직접 Hash() 함수를 구현해보도록 하자. 그 전에 함수의 시그니처를 정의해야 하는데,
편의상 버킷의 갯수 $N$을 매개변수화 하지 말고 Hash() 함수의 인자 size로 포함시키도록 하자.
또한 임의의 객체를 직접 입력받기는 곤란하므로 호출자가 직접 객체로부터 64비트 정수를 생성하여
Hash() 함수에는 64비트 정수를 key로 넘기도록 하자.
즉 함수의 시그니처는 다음과 같다. (요즘 Go를 해보고 있어서 Go lang으로..)
func Hash(key int64, size int) int
Naive Implementation
Consistent hash의 monotonicity 속성에 의해 $n$번째 버킷을 추가할 때 키의 버킷이 $n$으로 바뀔 확률이 $\frac{1}{n}$임을 이용하면 쉽게 구현할 수 있다. 매번 같은 확률을 제공하기 위해서 키를 random 함수의 시드로 제공한다.
func Hash(key int64, numBucket int) int {
rand.Seed(key)
bucket := -1
for i := 0; i < numBucket; i++ {
if rand.Float64() < (1.0 / float64(i+1)) {
bucket = i
}
}
return bucket
}
헐 벌써 구현이 끝난 것 같다. 시간복잡도도 겨우 $O(size)$ 다!
$O(logN)$ Implementation
시간 복잡도를 줄이기 앞서, 키의 해시 값이 버킷 사이즈가 증가함에 따라서 어떻게 바뀌어야 하는지 생각해보자. 다음은 위의 naive 구현을 이용하여 20개의 키 key1, key2, …, key20의 해시값의 변화하는 양상을 직접 계산하여 표로 나타내 본 것이다.
| size | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| key1 | 0 | 0 | 2 | 3 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| key2 | 0 | 1 | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 16 | 16 | 16 | 16 |
| key3 | 0 | 0 | 0 | 3 | 4 | 4 | 4 | 7 | 7 | 7 | 7 | 7 | 7 | 13 | 13 | 13 | 13 | 13 | 13 | 13 |
| key4 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 8 | 8 | 8 | 8 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| key5 | 0 | 0 | 0 | 0 | 4 | 4 | 4 | 4 | 4 | 4 | 10 | 10 | 10 | 13 | 13 | 13 | 13 | 13 | 13 | 13 |
| key6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
| key7 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 7 | 7 | 7 | 7 | 7 | 7 | 13 | 13 | 13 | 13 | 13 | 13 | 13 |
| key8 | 0 | 0 | 0 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| key9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 13 | 13 | 15 | 15 | 15 | 15 | 15 |
| key10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| key11 | 0 | 1 | 1 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| key12 | 0 | 0 | 2 | 2 | 4 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| key13 | 0 | 1 | 1 | 1 | 1 | 1 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 17 | 17 | 17 |
| key14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 |
| key15 | 0 | 1 | 2 | 2 | 2 | 2 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 |
| key16 | 0 | 0 | 0 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 19 |
| key17 | 0 | 1 | 1 | 1 | 1 | 5 | 5 | 5 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
| key18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 7 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 18 | 18 |
| key19 | 0 | 0 | 2 | 3 | 3 | 3 | 6 | 6 | 8 | 8 | 8 | 11 | 12 | 12 | 14 | 14 | 14 | 14 | 14 | 14 |
| key20 | 0 | 0 | 2 | 2 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 15 | 15 | 15 | 15 | 15 |
버킷 개수가 증가함에 따라 키의 해시 결과가 달라진 경우 굵은 글씨로 표시했다. 아이디어는 이러한 해시 값의 변화가 버킷 크기가 커질수록 점점 드물게 일어난다는 점이다. 버킷이 1개부터 $N$개까지 추가될 때 특정 키의 해시 값이 변경되는 (또는 키가 새로운 버킷에 할당되는) 횟수의 기댓값은
이다. 즉 다음 변경 지점이 언제일지 상수 시간에 구할 수 있다면 $O(logN)$의 시간복잡도를 만들 수 있다. 이렇게 다음 변경지점으로 점프하는 알고리즘의 과정 때문에 Jump Consistent Hash라고 불린다.
이제 점프를 계산해보자. 가장 마지막에 점프했을 떄 해시 값이 (즉 점프했을 때 추가되었던 버킷의 번호가) $b$ 라고 할때 다음 점프의 거리를 확률변수 $J_{b}$라고 하자. 이 때 $J_{b}$에 대한 이산확률분포는 다음과 같다.
식보다는 그림이 좀 더 보기 편하다. 수직선 위에 점 $1-\frac{b+1}{b+2}$, $1-\frac{b+1}{b+3}$, … 을 찍어보면 각 점에서부터 1까지의 길이가 $P(J_{b} \ge b+2)$, $P(J_{b} \ge b+3)$, … 에 대응되게 된다.
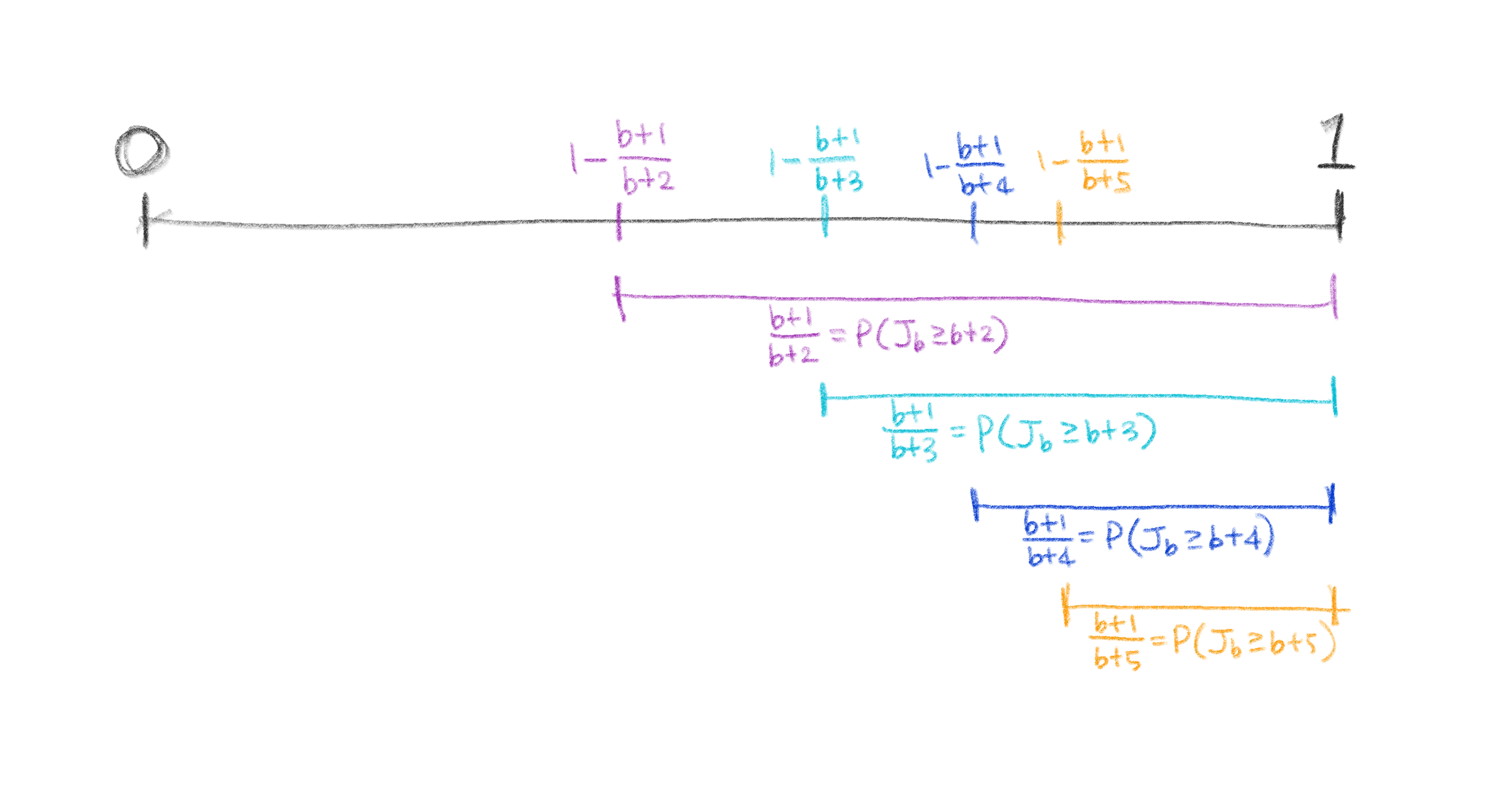
실제로 우리가 프로그램에서 사용하는 확률변수 rand.Float64()는 0 에서 1 사이의 uniform distribution인데,
랜덤 값이 어디에 속하느냐에 따라서 다음과 같이 $J_{b}$를 매겨주면 $J_{b}$는 우리 위에서 정의한 이산확률분포를 따르는 확률변수가 된다!
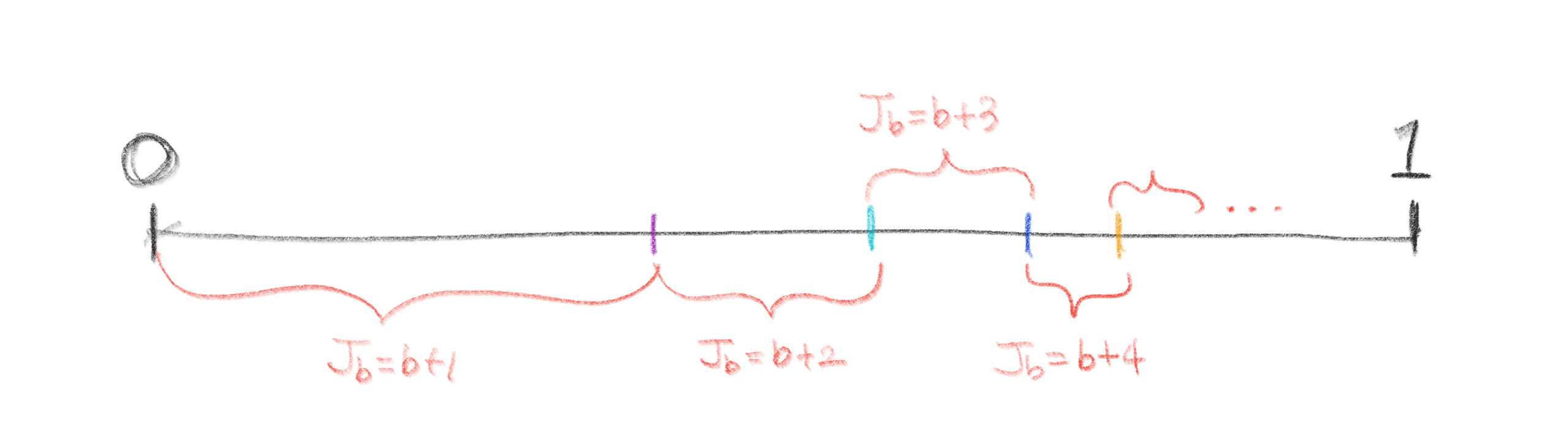
실제 식을 구하기 위해 rand.Float64()의 확률변수를 $X$라고 정의하고
$P(J_{b} \ge i) = \frac{b+1}{i}$의 확률이 나오도록 식을 변형해보자.
즉 j = int(float64(b+1) / rand.Float64()) 인 셈이다! 이를 코드로 옮겨보면 다음과 같다.
func Hash2(key int64, size int) int {
rand.Seed(key)
bucket := -1
jumped := 0
for jumped < size {
bucket = jumped
jumped = int(float64(bucket+1) / rand.Float64())
}
return bucket
}
이 코드를 pseudo random 값을 직접 생성하는 코드로 변경하면 맨 처음에 소개했던 코드를 만들 수 있다!
분산 환경에서의 Jump Consistent Hash
Jump Consistent Hash가 어떻게 분산 환경에서 사용되는지 알아보기 위해 간단한 분산 key-value 저장소를 만드는 경우를 생각해 보자. 간단한 설명을 위해서 key는 64비트 정수이고 replication은 없다고 가정하겠다. 저장소는 총 $N$개의 버킷으로 구성된다.
저장소의 구현은 간단하다.
- 저장소에서 Jump Consistent Hash를 사용해서 특정 키가 어느 버킷에 저장되어 있는지
Hash(key, N)으로 구할 수 있다. - 새로운 버킷이 저장소 클러스터에 추가된다면 객체가 저장되어야 하는 버킷은
Hash(key, N+1)로 바뀐다. 다행히도 consistent hash의 monotonicity 속성에 의해 해시값이 바뀌는 객체의 개수는 최소화된다. - 버킷이 저장소 클러스터에서 제외된다면 객체가 저장되어야 하는 버킷은
Hash(key, N-1)로 바뀐다.
생각이 많았던 독자분들은 아마 세번째 사항이 마음에 걸렸을 것이다. Hash(key, N)이 버킷의 인덱스를 나타낸다면
마지막 인덱스의 버킷이 제거될 때는 Hash(key, N-1)을 통해 객체의 재배치를 최소화할 수 있지만 마지막 인덱스가 아닌 다른
인덱스의 버킷이 제거될 때에는 Hash(key, N-1)을 통해 재배치된 객체들은 버킷이 한 칸씩 밀려 왕창 이동을 해야 되기 때문이다.
아니 삭제를 할 수 없나요??
여러 방법을 고민해 봤는데 제거된 버킷에 있던 객체만 재배치되는 방법은 아무래도 떠오르지 않았다. 이는 근본적으로 Jump Consistent Hash는 어떤 버킷이 없어졌는지를 파악할 수 없고 단지 버킷의 개수만을 인자로 받기 때문이다. 다만 임시방편으로 제외된 버킷의 인덱스에 기존의 $N$번째 버킷을 대응시키는 방법을 쓸 수 있다.
간단한 예를 들어 네 개의 버킷 Alice, Bob, Charlie, David이 있었다고 하자. 각 버킷은 0, 1, 2, 3의 인덱스를 가지고 있었다.
| Bucket | Index |
|---|---|
| Alice | 0 |
| Bob | 1 |
| Charlie | 2 |
| David | 3 |
각 버킷에는 4개의 객체 apple, banana, cherry, durian 이 있었고 각 객체의 해시 결과는 다음과 같았다. 운이 좋게도, apple 객체는 Alice 버킷에, banana 객체는 Bob 버킷에, cherry 객체는 Charlie 버킷에, durian 객체는 David 버킷에 골고루 분포되어 저장되었다.
| size | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| apple | 0 | 0 | 0 | 0 (Alice) |
| banana | 0 | 1 | 1 | 1 (Bob) |
| cherry | 0 | 1 | 2 | 2 (Charlie) |
| durian | 0 | 1 | 2 | 3 (David) |
시간이 흘러 David 버킷이 제거된다면, 버킷과 인덱스는 다음과 같이 된다.
| Bucket | Index |
|---|---|
| Alice | 0 |
| Bob | 1 |
| Charlie | 2 |
이 때 각 객체는 size가 3이었을 때의 해시를 이용하면 durian 객체가 David 버킷에서 Charlie 버킷으로 이동하게 된다. 이 때 David 버킷에 있던 객체만 재배치됨이 반드시 보장된다.
| size | 1 | 2 | 3 |
|---|---|---|---|
| apple | 0 | 0 | 0 (Alice) |
| banana | 0 | 1 | 1 (Bob) |
| cherry | 0 | 1 | 2 (Charlie) |
| durian | 0 | 1 | 2 (Charlie) |
하지만 만약 Alice 버킷이 제거되게 된다면 버킷 인덱스가 꼬이게 된다.
| Bucket | Index |
|---|---|
| Bob | 1 |
| Charlie | 2 |
| David | 3 |
버킷 인덱스를 정상화시키기 위해 가장 마지막 버킷인 David의 인덱스를 0으로 바꾸면 다음과 같아진다.
| Bucket | Index |
|---|---|
| David | 0 |
| Bob | 1 |
| Charlie | 2 |
이 상태에서 size가 3일때의 해시를 이용하면 apple 객체가 David 버킷으로, durian 객체가 Charlie 버킷으로 이동하게 된다. 변경사항은 monotonic하지 않아서 David 버킷은 제거되지 않았음에도 durian 객체는 Charlie 버킷으로 이동해야 한다! 정확히는 마지막 버킷인 David에서는 변경사항이 반드시 발생한다.
| size | 1 | 2 | 3 |
|---|---|---|---|
| apple | 0 | 0 | 0 (David) |
| banana | 0 | 1 | 1 (Bob) |
| cherry | 0 | 1 | 2 (Charlie) |
| durian | 0 | 1 | 2 (Charlie) |
그래도 재배치되는 객체는 최대 두 개의 버킷으로 좁힐 수 있다. 만약 버킷의 lifecycle을 완전히 컨트롤 할 수 있는 상태라면 (버킷이 자연사하지 않는다면) 가장 마지막에 추가된 버킷을 가장 먼저 제거하도록 하면 이러한 상황을 피할 수 있다.
마치며
마지막에 탈이 나긴 했지만, Jump Consistent Hash는 여전히 훌륭한 consistent hash 알고리즘이다. 무엇보다 코드가 너무 짧기에 진입장벽이 매우 낮다. (나도 consistent hash에 대한 지식이 전무한 상태였는데 우연히 Jump Consistent hash의 구현 코드를 보고 John Lamping의 논문을 읽어보게 되었다.)
Practical한 측면으로는 계산속도가 매우 빠르며 메모리 소비는 $O(1)$에 불과하다. 또한 확률변수를 인위적으로 구현했기 때문에 고르게 분산되는 정도는 거의 완벽하다! 각 버킷에 저장되는 객체의 갯수에 대한 표준편차는 고작 0.00000000764이다.
이 외에도 Multi-probe consistent hashing이나 Maglev hashing 등의 다른 consistent hashing 방법이 있다고 한다. (Jump Consistent Hash까지 포함하여 셋 다 구글에서 개발한 알고리즘이라고 한다.) 나는 이 글을 쓰느라 너무 지쳐서 읽을 힘이 없어 읽지 못했지만 관심있는 분은 찾아서 읽어보시길 바란다!